Universal Adversarial Perturbations Through the Lens of Deep Steganography: A Fourier Perspective
Abstract
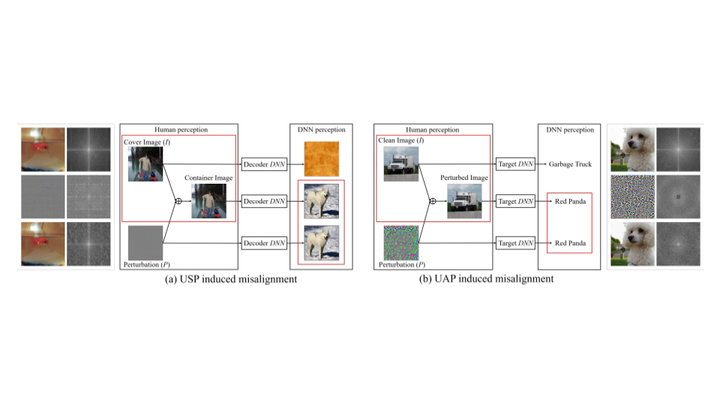
The booming interest in adversarial attacks stems from a misalignment between human vision and a deep neural network (DNN), i.e. a human imperceptible perturbation fools the DNN. Moreover, a single perturbation, often called universal adversarial perturbation (UAP), can be generated to fool the DNN for most images. A similar misalignment phenomenon has recently also been observed in the deep steganography task, where a decoder network can retrieve a secret image back from a slightly perturbed cover image. We attempt explaining the success of both in a unified manner from the Fourier perspective. We perform task-specific and joint analysis and reveal that (a) frequency is a key factor that influences their performance based on the proposed entropy metric for quantifying the frequency distribution; (b) their success can be attributed to a DNN being highly sensitive to high-frequency content. We also perform feature layer analysis for providing deep insight on model generalization and robustness. Additionally, we propose two new variants of universal perturbations: (1) Universal Secret Adversarial Perturbation (USAP) that simultaneously achieves attack and hiding; (2) high-pass UAP (HP-UAP) that is less visible to the human eye.
Philipp Benz
Research Team Manager @ Deeping Source (Ph.D. @ KAIST)
My research interest is in Deep Learning with a focus on robustness and security.