Abstract
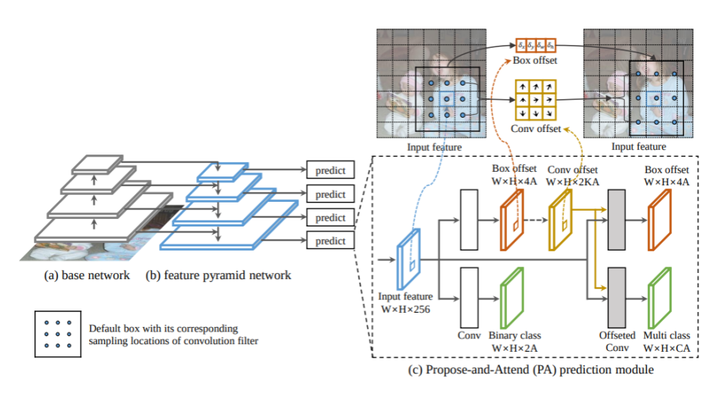
We present a simple yet effective prediction module for a one-stage detector. The main process is conducted in a coarse-to-fine manner. First, the module roughly adjusts the default boxes to well capture the extent of target objects in an image. Second, given the adjusted boxes, the module aligns the receptive field of the convolution filters accordingly, not requiring any embedding layers. Both steps build a propose-and-attend mechanism, mimicking two-stage detectors in a highly efficient manner. To verify its effectiveness, we apply the proposed module to a basic one-stage detector SSD. Our final model achieves an accuracy comparable to that of state-of-the-art detectors while using a fraction of their model parameters and computational overheads. Moreover, we found that the proposed module has two strong applications. 1) The module can be successfully integrated into a lightweight backbone, further pushing the efficiency of the one-stage detector. 2) The module also allows train-from-scratch without relying on any sophisticated base networks as previous methods do.
Philipp Benz
Research Team Manager @ Deeping Source (Ph.D. @ KAIST)
My research interest is in Deep Learning with a focus on robustness and security.