 Adversarial Machine Learning and Beyond
Adversarial Machine Learning and Beyond
Abstract
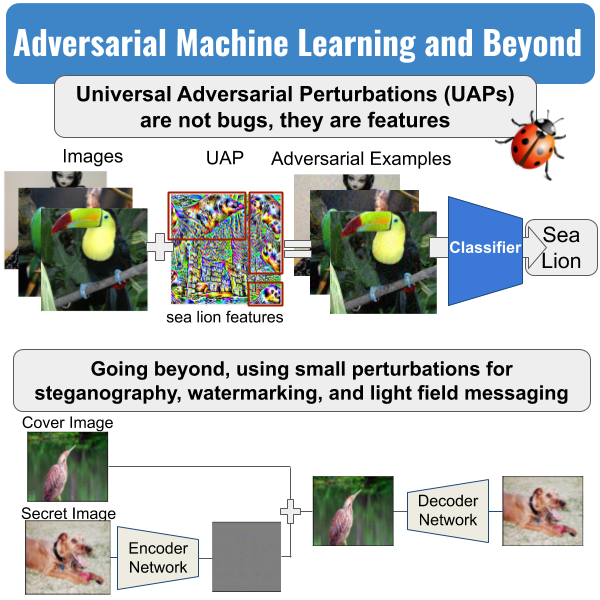
Despite their great success and popularity, deep neural networks are widely known to be vulnerable to adversarial examples, i.e. small human imperceptible perturbations fooling a target model. This intriguing phenomenon has inspired numerous techniques for attack and defense. More strikingly, a single perturbation has been found to fool a model for most images. In this talk, we will give an introduction to adversarial attack and defense as well as the most recent progress on universal adversarial perturbations. Beyond the adversarial use, we also show that small imperceptible perturbations can be utilized to hide useful information for steganography, watermarking, and light field messaging.
Philipp Benz
Research Team Manager @ Deeping Source (Ph.D. @ KAIST)
My research interest is in Deep Learning with a focus on robustness and security.