 Adversarial Transferability and Beyond
Adversarial Transferability and Beyond
Abstract
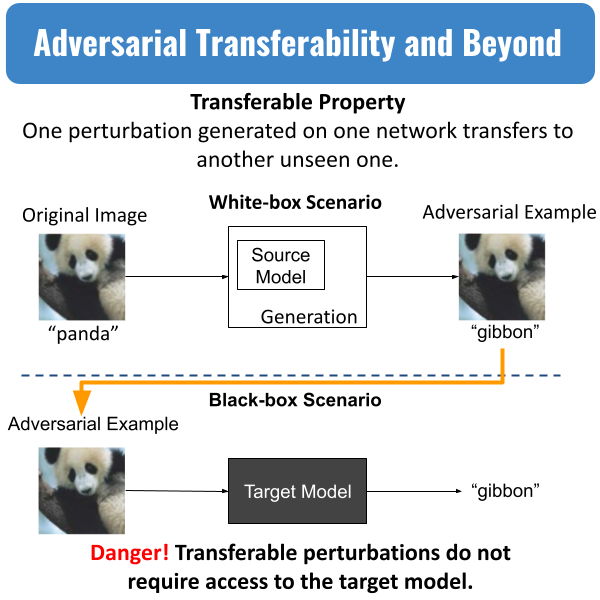
Deep Neural Networks have achieved great success in various vision tasks in recent years. However, they remain vulnerable to adversarial examples, i.e. small human imperceptible perturbations fooling a target model. This intriguing phenomenon has inspired numerous techniques for attack and defense. In this talk, we will mainly focus on the transferability property that makes adversarial examples so dangerous as well as some of the theories to understand this intriguing phenomenon. Here, transferability refers to the property that adversarial examples generated on one model successfully transfer to another, unseen model, therefore constituting a black-box attack.
Philipp Benz
Research Team Manager @ Deeping Source (Ph.D. @ KAIST)
My research interest is in Deep Learning with a focus on robustness and security.