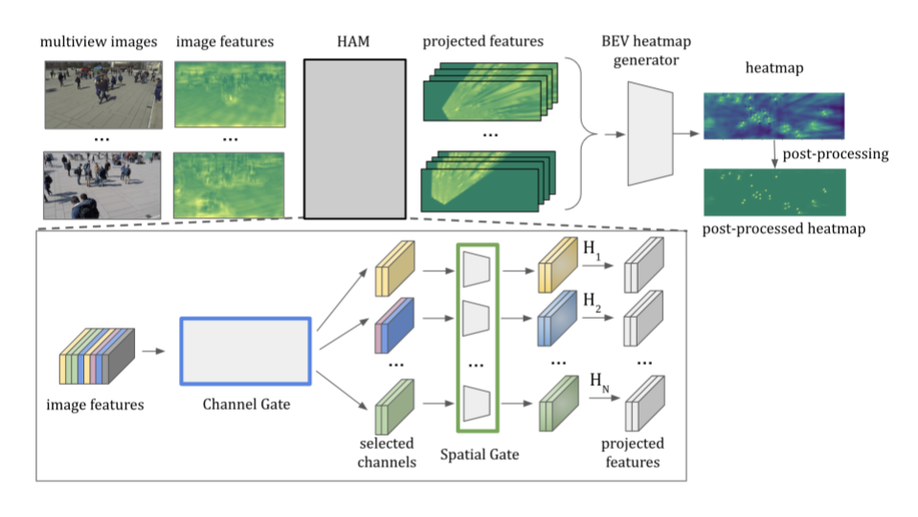
Booster-SHOT: Boosting Stacked Homography Transformations for Multiview Pedestrian Detection with Attention
We propose Homography Attention Module (HAM) which is shown to boost the performance of existing end-to-end multiview detection approaches by utilizing a novel channel gate and spatial gate. Additionally, we propose Booster-SHOT, an end-to-end convolutional approach to multiview pedestrian detection incorporating our proposed HAM as well as elements from previous approaches such as view-coherent augmentation or stacked homography transformations.
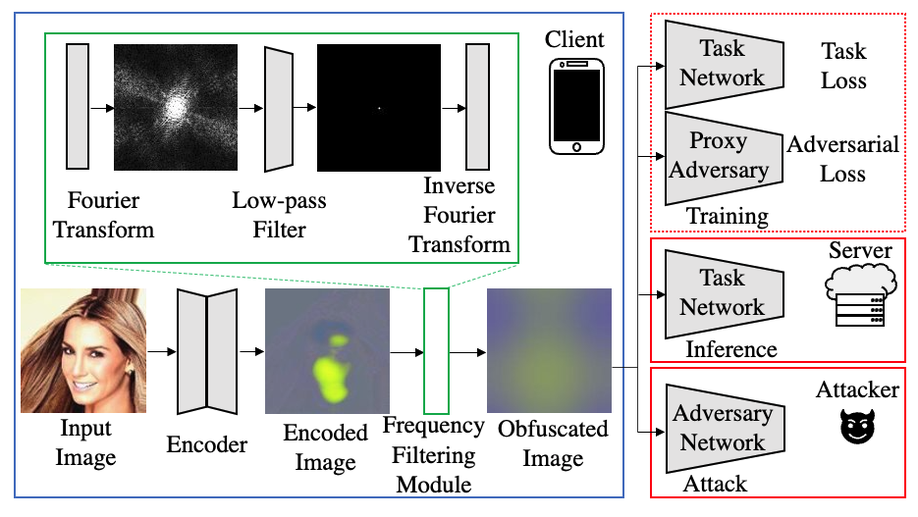
Privacy Safe Representation Learning via Frequency Filtering Encoder
Training a reconstruction attacker can successfully recover the original image of existing Adversarial Representation Learning (ARL) methods. We introduce a novel ARL method enhanced through low-pass filtering, limiting the available information amount to be encoded in the frequency domain.
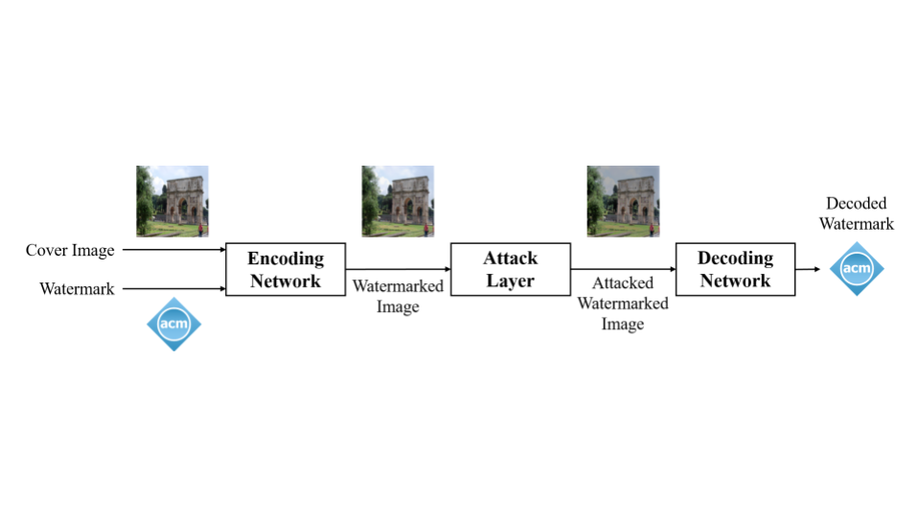
Towards Robust Deep Hiding Under Non-Differentiable Distortions for Practical Blind Watermarking
Despite its wide usage, the gain of enhanced robustness from attack simulation layer (ASL) is usually interpreted through the lens of augmentation, while our work explores this gain from a new perspective by disentangling the forward and backward propagation of such ASL.
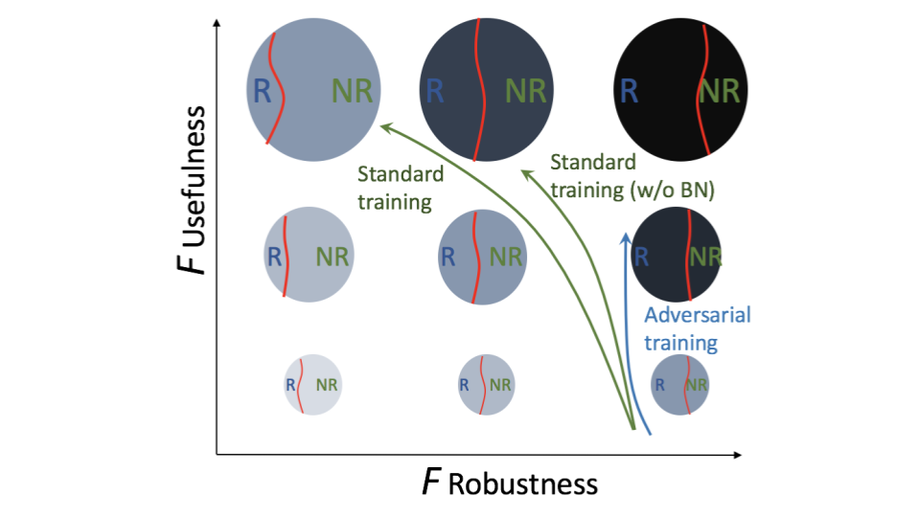
Batch Normalization Increases Adversarial Vulnerability and Decreases Adversarial Transferability: A Non-Robust Feature Perspective
Batch normalization is observed to increase the model accuracy while at the cost of adversarial robustness. We conjecture that the increased adversarial vulnerability is caused by BN shifting the model to rely more on non-robust features.
Data-Free Universal Adversarial Perturbation and Black-Box Attack
Towards strictly data-free untargeted UAP, our work proposes to exploit artificial Jigsaw images as the training samples, demonstrating competitive performance. We further investigate the possibility of exploiting the UAP for a data-free black-box attack which is arguably the most practical yet challenging threat model. We demonstrate that there exists optimization-free repetitive patterns which can successfully attack deep models.
A Survey On Universal Adversarial Attack
This survey summarizes the recent progress on universal adversarial attacks, discussing the challenges from both the attack and defense sides, as well as the reason for the existence of UAP. Additionally, universal attacks in a wide range of applications beyond deep classification are also covered.
A Brief Survey on Deep Learning Based Data Hiding, Steganography and Watermarking
We conduct a brief yet comprehensive review of existing literature and outline three meta-architectures. Based on this, we summarize specific strategies for various applications of deep hiding, including steganography, light field messaging and watermarking. Finally, further insight into deep hiding is provided through incorporating the perspective of adversarial attack.
Universal Adversarial Training with Class-Wise Perturbations
Universal adversarial training (UAT) optimizes a single perturbation for all training samples in the mini-batch. We find that a UAP does not attack all classes equally. Inspired by this observation, we identify it as the source of the model having unbalanced robustness. To this end, we improve the UAT by proposing to utilize class-wise UAPs during adversarial training.
Trade-off Between Accuracy, Robustness, and Fairness of Deep Classifiers
Deep classifiers trained on balanced datasets exhibit a class-wise imbalance, which is even more severe for adversarially trained models. We propose a class-wise loss re-weighting to obtain more fair standard and robust classifiers. The final results suggest, that there exists a triangular trade-off between accuracy, robustness, and fairness.
Is FGSM Optimal or Necessary for L∞ Adversarial Attack?
We identify two drawbacks of MI-FGSM; inducing higher average pixel discrepancy to the image as well as making the current iteration update overly dependent on the historical gradients. We propose a new momentum-free iterative method that processes the gradient with a generalizable Cut & Norm operation instead of a sign operation.
Backpropagating Smoothly Improves Transferability of Adversarial Examples
We conjecture that the reason that backpropagating linearly (LinBP) improves the transferability is mainly due to a continuous approximation for the ReLU in the backward pass. We propose backpropagating continuously (ConBP) that adopts a smooth yet non-linear gradient approximation. Our ConBP consistently achieves equivalent or superior performance than the recently proposed LinBP
Towards Simple Yet Effective Transferable Targeted Adversarial Attacks
We revisit the transferable adversarial attacks and improve it from two perspectives; First, we identify over-fitting as one major factor that hinders transferability, for which we propose to augment the network input and/or feature layers with noise. Second, we propose a new cross-entropy loss with two ends; One for pushing the sample far from the source class, i.e. ground-truth class, and the other for pulling it close to the target class.
Stochastic Depth Boosts Transferability of Non-Targeted and Targeted Adversarial Attacks
In contrast to most existing works that manipulate the image input for boosting transferability, our work manipulates the model architecture. Specifically, we boost the transferability with stochastic depth by randomly removing a subset of layers in networks with skip connections. Technical-wise, our proposed approach is mainly inspired by previous work improving the network generalization with stochastic depth. Motivation-wise, our approach of removing residual module instead of skip connection is inspired by the known finding that transferability of adversarial examples are positively related to local linearity of DNNs.
On Strength and Transferability of Adversarial Examples: Stronger Attack Transfers Better
We revisit adversarial attacks by perceiving it as shifting the sample semantically close to or far from a certain class, i.e. interest class. With this perspective, we introduce a new metric called interest class rank (ICR), i.e. the rank of interest class in the adversarial example, to evaluate adversarial strength.
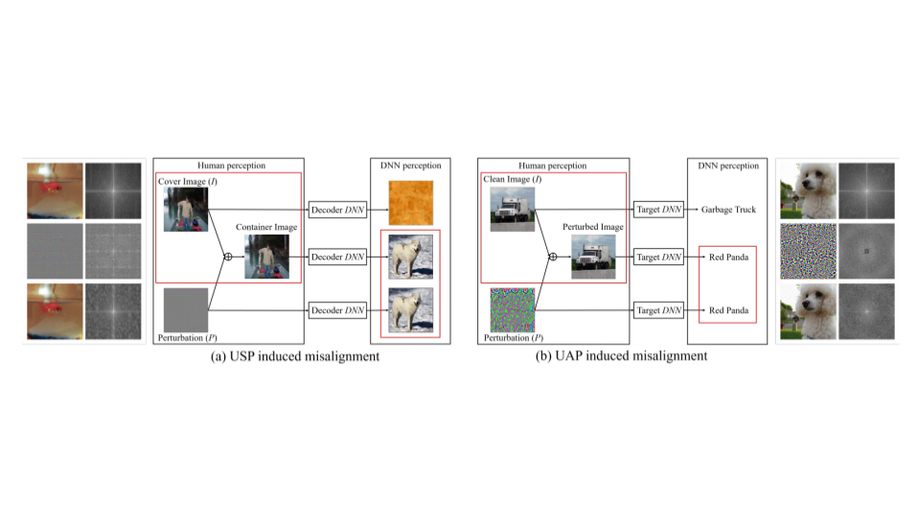
Universal Adversarial Perturbations Through the Lens of Deep Steganography: A Fourier Perspective
The booming interest in adversarial attacks stems from a misalignment between human vision and a deep neural network (DNN), i.e. a human imperceptible perturbation fools the DNN. A similar misalignment phenomenon has recently also been observed in the deep steganography task, where a decoder network can retrieve a secret image back from a slightly perturbed cover image. We attempt explaining the success of both in a unified manner from the Fourier perspective. Additionally, we propose two new variants of universal perturbations (1) Universal Secret Adversarial Perturbation; (2) high-pass UAP.
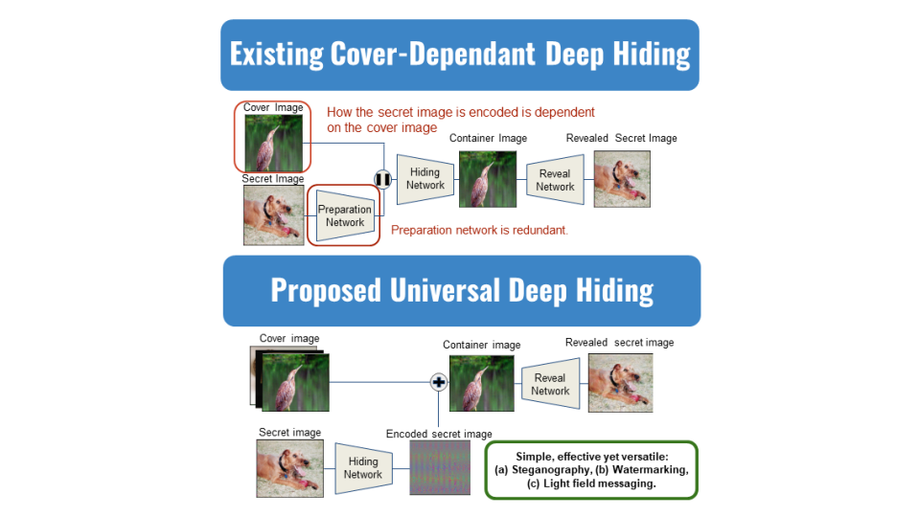
UDH: Universal Deep Hiding for Steganography, Watermarking, and Light Field Messaging
We propose a novel universal deep hiding (UDH) meta-architecture to disentangle the encoding of a secret image from the cover image. Our analysis demonstrates that the success of deep steganography can be attributed to a frequency discrepancy between the cover image and the encoded secret image. Exploiting UDHs universal property, we extend UDH for universal watermarking and light field messaging.
Robustness May Be at Odds with Fairness: An Empirical Study on Class-wise Accuracy
We propose an empirical study on the class-wise accuracy and robustness of adversarially trained models. Our work aims to investigate the following questions (a) is the phenomenon of inter-class discrepancy universal regardless of datasets, model architectures and optimization hyper-parameters? (b) If so, what can be possible explanations for the inter-class discrepancy? (c) Can the techniques proposed in the long tail classification be readily extended to adversarial training for addressing the inter-class discrepancy?
ResNet or DenseNet? Introducing Dense Shortcuts to ResNet
ResNet or DenseNet? This paper provides a unified perspective of dense summation to analyze them, which facilitates a better understanding of their core difference. We further propose dense weighted normalized shortcuts as a solution to the dilemma between them. Our proposed dense shortcut inherits the design philosophy of simple design in ResNet and DenseNet.
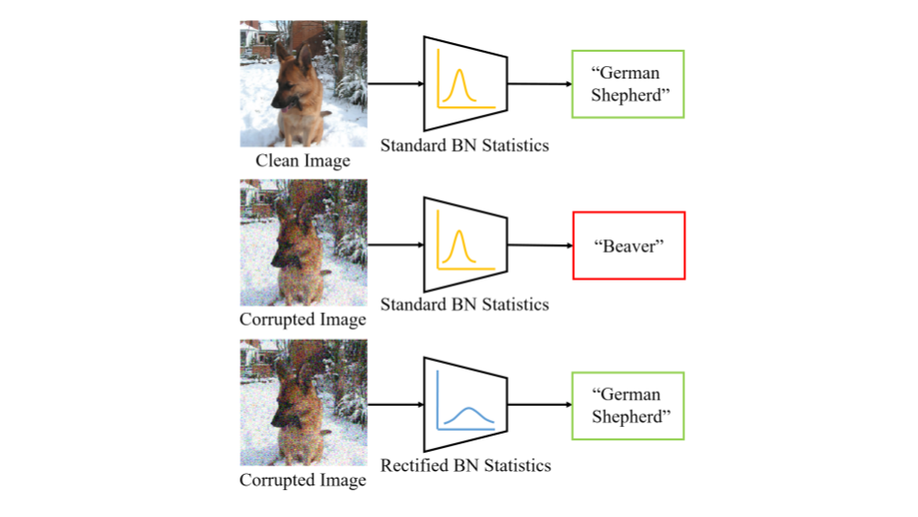
Revisiting Batch Normalization for Improving Corruption Robustness
The performance of DNNs trained on clean images has been shown to decrease when the test images have common corruptions. In this work, we interpret corruption robustness as a domain shift and propose to rectify batch normalization (BN) statistics for improving model robustness. This is motivated by perceiving the shift from the clean domain to the corruption domain as a style shift that is represented by the BN statistics. We find that simply estimating and adapting the BN statistics on a few (32 for instance) representation samples, without retraining the model, improves the corruption robustness by a large margin.
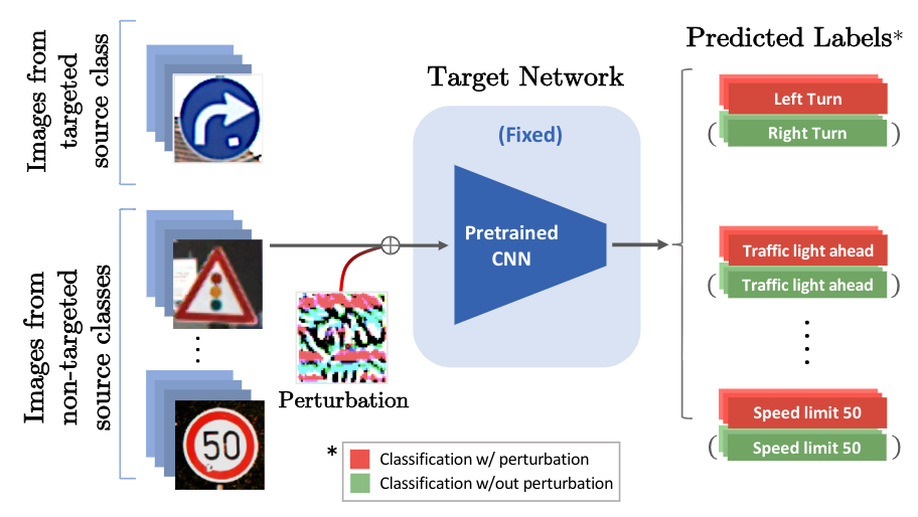
Double Targeted Universal Adversarial Perturbations
We introduce a double targeted universal adversarial perturbations (DT-UAPs) to bridge the gap between the instance-discriminative image-dependent perturbations and the generic universal perturbations. This universal perturbation attacks one targeted source class to a sink class, while having a limited adversarial effect on other non-targeted source classes, for avoiding raising suspicions. Targeting the source and sink class simultaneously, we term it double targeted attack (DTA).

Understanding Adversarial Examples from the Mutual Influence of Images and Perturbations
We propose to treat the DNN logits as a vector for feature representation, and exploit them to analyze the mutual influence of two independent inputs based on the Pearson correlation coefficient (PCC). Our analysis results suggest a new perspective towards the relationship between images and universal perturbations. Universal perturbations contain dominant features, and images behave like noise to them. This feature perspective leads to a new method for generating targeted universal adversarial perturbations using random source images.
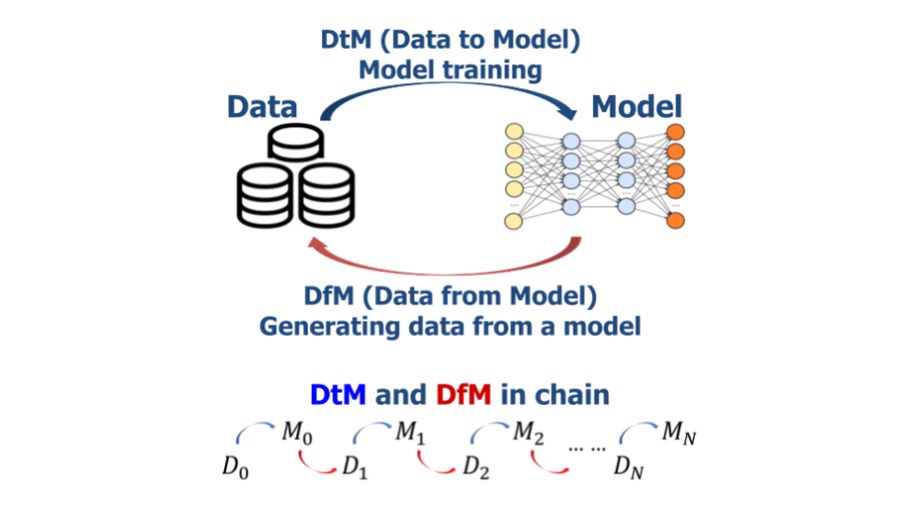
Data from Model: Extracting Data from Non-robust and Robust Models
The essence of deep learning is to exploit data to train a deep neural network (DNN) model. This work explores the reverse process of generating data from a model, attempting to reveal the relationship between the data and the model. We repeat the process of Data to Model (DtM) and Data from Model (DfM) in sequence and explore the loss of feature mapping information by measuring the accuracy drop on the original validation dataset.
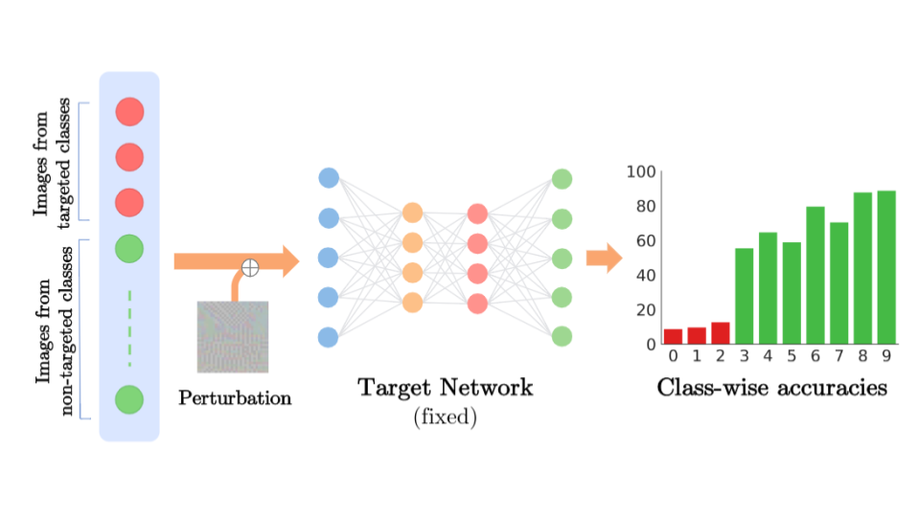
CD-UAP: Class Discriminative Universal Adversarial Perturbation
We propose a new universal attack method to generate a single perturbation that fools a target network to misclassify only a chosen group of classes, while having limited influence on the remaining classes, which is termed class discriminative universal adversarial perturbation (CD-UAP).
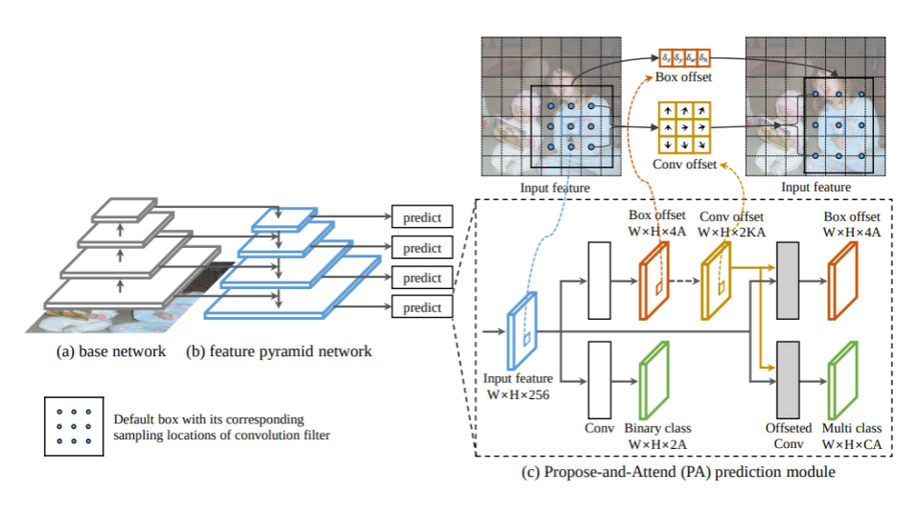
Propose-and-Attend Single Shot Detector
We present a simple yet effective prediction module for a one-stage detector. The main process is conducted in a coarse-to-fine manner. First, the module roughly adjusts the default boxes to well capture the extent of target objects in an image. Second, given the adjusted boxes, the module aligns the receptive field of the convolution filters accordingly, not requiring any embedding layers. Both steps build a propose-and-attend mechanism, mimicking two-stage detectors in a highly efficient manner.
Revisiting Residual Networks with Nonlinear Shortcuts
We revisit ResNet identity shortcut and propose RGSNets which are based on a new nonlinear ReLU Group Normalization (RG) shortcut, outperforming the existing ResNet by a relatively large margin. Our work is inspired by previous findings that there is a trade-off between representational power and gradient stability in deep networks and that the identity shortcut reduces the representational power.

Fast Perception, Planning, and Execution for a Robotic Butler: Wheeled Humanoid M-Hubo
We propose a unique strategy of integrating a 3D object detection pipeline with a kinematically optimal manipulation planner to significantly increase speed performance at runtime. In addition, we develop a new robotic butler system for a wheeled humanoid that is capable of fetching requested objects at 24% of the speed a human needs to fulfill the same task.
Sensor-Based Mobile Robot Navigation via Deep Reinforcement Learning
We propose a novel model for mobile robot navigation using deep reinforcement learning. In our navigation tasks, no information about the environment is given to the robot beforehand. Additionally, the positions of obstacles and goal change in every episode. In order to succeed under these conditions, we combine several Q-learning techniques.